Project: Write an Algorithm for a Dog Identification App¶
Why We're Here¶
In this notebook, we will be developing an algorithm that could be used as part of a mobile or web app. At the end of this project, the code will accept any user-supplied image as input. If a dog is detected in the image, it will provide an estimate of the dog's breed. If a human is detected, it will provide an estimate of the dog breed that is most resembling.

In this real-world setting, we will need to piece together a series of models to perform different tasks; for instance, the algorithm that detects humans in an image will be different from the CNN that infers dog breed. There are many points of possible failure, and no perfect algorithm exists.
The Road Ahead¶
We break the notebook into separate steps. Feel free to use the links below to navigate the notebook.
- Step 0: Import Datasets
- Step 1: Detect Humans
- Step 2: Detect Dogs
- Step 3: Create a CNN to Classify Dog Breeds (from Scratch)
- Step 4: Use a CNN to Classify Dog Breeds (using Transfer Learning)
- Step 5: Create a CNN to Classify Dog Breeds (using Transfer Learning)
- Step 6: Write your Algorithm
- Step 7: Test Your Algorithm
Step 0: Import Datasets¶
Import Dog Dataset¶
In the code cell below, we import a dataset of dog images. We populate a few variables through the use of the load_files function from the scikit-learn library:
train_files,valid_files,test_files- numpy arrays containing file paths to imagestrain_targets,valid_targets,test_targets- numpy arrays containing onehot-encoded classification labelsdog_names- list of string-valued dog breed names for translating labels
from sklearn.datasets import load_files
from keras.utils import np_utils
import numpy as np
from glob import glob
# define function to load train, test, and validation datasets
def load_dataset(path):
data = load_files(path)
dog_files = np.array(data['filenames'])
dog_targets = np_utils.to_categorical(np.array(data['target']), 133)
return dog_files, dog_targets
# load train, test, and validation datasets
train_files, train_targets = load_dataset('/data/dog_images/train')
valid_files, valid_targets = load_dataset('/data/dog_images/valid')
test_files, test_targets = load_dataset('/data/dog_images/test')
# load list of dog names
dog_names = [item[20:-1] for item in sorted(glob("/data/dog_images/train/*/"))]
# print statistics about the dataset
print('There are %d total dog categories.' % len(dog_names))
print('There are %s total dog images.\n' % len(np.hstack([train_files, valid_files, test_files])))
print('There are %d training dog images.' % len(train_files))
print('There are %d validation dog images.' % len(valid_files))
print('There are %d test dog images.'% len(test_files))
Import Human Dataset¶
In the code cell below, we import a dataset of human images, where the file paths are stored in the numpy array human_files.
import random
random.seed(8675309)
# load filenames in shuffled human dataset
human_files = np.array(glob("/data/lfw/*/*"))
random.shuffle(human_files)
# print statistics about the dataset
print('There are %d total human images.' % len(human_files))
Step 1: Detect Humans¶
We use OpenCV's implementation of Haar feature-based cascade classifiers to detect human faces in images. OpenCV provides many pre-trained face detectors, stored as XML files on github. We have downloaded one of these detectors and stored it in the haarcascades directory.
In the next code cell, we demonstrate how to use this detector to find human faces in a sample image.
import cv2
import matplotlib.pyplot as plt
%matplotlib inline
# extract pre-trained face detector
face_cascade = cv2.CascadeClassifier('haarcascades/haarcascade_frontalface_alt.xml')
# load color (BGR) image
img = cv2.imread(human_files[3])
# convert BGR image to grayscale
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# find faces in image
faces = face_cascade.detectMultiScale(gray)
# print number of faces detected in the image
print('Number of faces detected:', len(faces))
# get bounding box for each detected face
for (x,y,w,h) in faces:
# add bounding box to color image
cv2.rectangle(img,(x,y),(x+w,y+h),(255,0,0),2)
# convert BGR image to RGB for plotting
cv_rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# display the image, along with bounding box
plt.imshow(cv_rgb)
plt.show()

Before using any of the face detectors, it is standard procedure to convert the images to grayscale. The detectMultiScale function executes the classifier stored in face_cascade and takes the grayscale image as a parameter.
In the above code, faces is a numpy array of detected faces, where each row corresponds to a detected face. Each detected face is a 1D array with four entries that specifies the bounding box of the detected face. The first two entries in the array (extracted in the above code as x and y) specify the horizontal and vertical positions of the top left corner of the bounding box. The last two entries in the array (extracted here as w and h) specify the width and height of the box.
Writing a Human Face Detector¶
We can use this procedure to write a function that returns True if a human face is detected in an image and False otherwise. This function, aptly named face_detector, takes a string-valued file path to an image as input and appears in the code block below.
# returns "True" if face is detected in image stored at img_path
def face_detector(img_path):
img = cv2.imread(img_path)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
faces = face_cascade.detectMultiScale(gray)
return len(faces) > 0
Assessing the Human Face Detector¶
Ideally, we would like 100% of human images with a detected face and 0% of dog images with a detected face. We will see that our algorithm falls short of this goal, but still gives acceptable performance. We extract the file paths for the first 100 images from each of the datasets and store them in the numpy arrays human_files_short and dog_files_short.
human_files_short = human_files[:100]
dog_files_short = train_files[:100]
# Do NOT modify the code above this line.
## TODO: Test the performance of the face_detector algorithm
## on the images in human_files_short and dog_files_short.
humans_rate = [face_detector(human) for human in human_files_short].count(True)/len(human_files_short)
dogs_rate = [face_detector(dog) for dog in dog_files_short].count(True)/len(dog_files_short)
humans_rate, dogs_rate
The rate for detected faces in the human files give us a 100 %, whereas 11 of the 100 dog pictures seem to be having human features as well. But this is an OK rate for this use case.
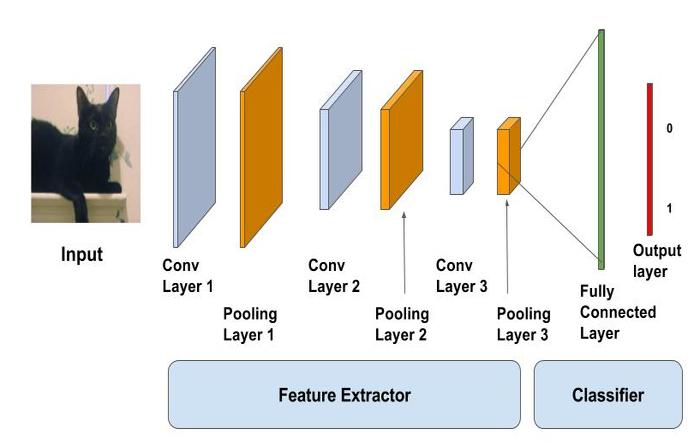
Question 2: This algorithmic choice necessitates that we communicate to the user that we accept human images only when they provide a clear view of a face (otherwise, we risk having unneccessarily frustrated users!). I think this is a reasonable expectation, because most pictures are all about capturing faces (this is what we usually consider as individual feature for people). Though, there are other ways to detect humans in images. For example, you could build a Convolutional Neural Network from scratch, upon labelled pictures with and without humans. A possible architecture could look like the following:

The important part is to reduce the width and the height and add more depth to the model to extract the features that are related to humans - and not only the face. After extracting features, you will get a percentage for the image containing a human or not.
Another way to try to extract features - without having to train a complete new network, is transfer learning:
- Transfer learning is based on the implication that the way a convolutional neural network behaves layer afer layer, is almost the same - even for datasets containing different sorts of pictures.
- You basically adopt a trained model's layers until it gets too specific (there are ways to visualize what actually happens inside - but you can try it out)
- Then you add the layers you want to extract the domain specific pictures with (this case: human/non-human)
- And then train it on your data
For the purpose of this notebook, I don't want to include this part here.
Step 2: Detect Dogs¶
In this section, we use a pre-trained ResNet-50 model to detect dogs in images. Our first line of code downloads the ResNet-50 model, along with weights that have been trained on ImageNet, a very large, very popular dataset used for image classification and other vision tasks. ImageNet contains over 10 million URLs, each linking to an image containing an object from one of 1000 categories. Given an image, this pre-trained ResNet-50 model returns a prediction (derived from the available categories in ImageNet) for the object that is contained in the image.
from keras.applications.resnet50 import ResNet50
# define ResNet50 model
ResNet50_model = ResNet50(weights='imagenet')
Pre-process the Data¶
When using TensorFlow as backend, Keras CNNs require a 4D array (which we'll also refer to as a 4D tensor) as input, with shape
$$ (\text{nb_samples}, \text{rows}, \text{columns}, \text{channels}), $$where nb_samples corresponds to the total number of images (or samples), and rows, columns, and channels correspond to the number of rows, columns, and channels for each image, respectively.
The path_to_tensor function below takes a string-valued file path to a color image as input and returns a 4D tensor suitable for supplying to a Keras CNN. The function first loads the image and resizes it to a square image that is $224 \times 224$ pixels. Next, the image is converted to an array, which is then resized to a 4D tensor. In this case, since we are working with color images, each image has three channels. Likewise, since we are processing a single image (or sample), the returned tensor will always have shape
The paths_to_tensor function takes a numpy array of string-valued image paths as input and returns a 4D tensor with shape
Here, nb_samples is the number of samples, or number of images, in the supplied array of image paths. It is best to think of nb_samples as the number of 3D tensors (where each 3D tensor corresponds to a different image) in your dataset!
from keras.preprocessing import image
from tqdm import tqdm
def path_to_tensor(img_path):
# loads RGB image as PIL.Image.Image type
img = image.load_img(img_path, target_size=(224, 224))
# convert PIL.Image.Image type to 3D tensor with shape (224, 224, 3)
x = image.img_to_array(img)
# convert 3D tensor to 4D tensor with shape (1, 224, 224, 3) and return 4D tensor
return np.expand_dims(x, axis=0)
def paths_to_tensor(img_paths):
list_of_tensors = [path_to_tensor(img_path) for img_path in tqdm(img_paths)]
return np.vstack(list_of_tensors)
Making Predictions with ResNet-50¶
Getting the 4D tensor ready for ResNet-50, and for any other pre-trained model in Keras, requires some additional processing. First, the RGB image is converted to BGR by reordering the channels. All pre-trained models have the additional normalization step that the mean pixel (expressed in RGB as $[103.939, 116.779, 123.68]$ and calculated from all pixels in all images in ImageNet) must be subtracted from every pixel in each image. This is implemented in the imported function preprocess_input. If you're curious, you can check the code for preprocess_input here.
Now that we have a way to format our image for supplying to ResNet-50, we are now ready to use the model to extract the predictions. This is accomplished with the predict method, which returns an array whose $i$-th entry is the model's predicted probability that the image belongs to the $i$-th ImageNet category. This is implemented in the ResNet50_predict_labels function below.
By taking the argmax of the predicted probability vector, we obtain an integer corresponding to the model's predicted object class, which we can identify with an object category through the use of this dictionary.
from keras.applications.resnet50 import preprocess_input, decode_predictions
def ResNet50_predict_labels(img_path):
# returns prediction vector for image located at img_path
img = preprocess_input(path_to_tensor(img_path))
return np.argmax(ResNet50_model.predict(img))
Write a Dog Detector¶
While looking at the dictionary, you will notice that the categories corresponding to dogs appear in an uninterrupted sequence and correspond to dictionary keys 151-268, inclusive, to include all categories from 'Chihuahua' to 'Mexican hairless'. Thus, in order to check to see if an image is predicted to contain a dog by the pre-trained ResNet-50 model, we need only check if the ResNet50_predict_labels function above returns a value between 151 and 268 (inclusive).
We use these ideas to complete the dog_detector function below, which returns True if a dog is detected in an image (and False if not).
### returns "True" if a dog is detected in the image stored at img_path
def dog_detector(img_path):
prediction = ResNet50_predict_labels(img_path)
return ((prediction <= 268) & (prediction >= 151))
Assessing the Dog Detector¶
### TODO: Test the performance of the dog_detector function
### on the images in human_files_short and dog_files_short.
humans_rate = [dog_detector(human) for human in human_files_short].count(True)/len(human_files_short)
dogs_rate = [dog_detector(dog) for dog in dog_files_short].count(True)/len(dog_files_short)
humans_rate, dogs_rate
As you can see, the dog_detector detects 0% of humans as a dog, whereas 100% of the dogs are actually correctly identified as dogs. This indeed is a perfect prediction of the pre-trained model for our chosen data.
Step 3: Create a CNN to Classify Dog Breeds (from Scratch)¶
Now that we have functions for detecting humans and dogs in images, we need a way to predict breed from images. In this step, we will create a CNN that classifies dog breeds. We must create your CNN from scratch (so, we can't use transfer learning yet!), and you must attain a test accuracy of at least 1%.
We mention that the task of assigning breed to dogs from images is considered exceptionally challenging. To see why, consider that even a human would have great difficulty in distinguishing between a Brittany and a Welsh Springer Spaniel.
| Brittany | Welsh Springer Spaniel |
|---|---|
 |
 |
It is not difficult to find other dog breed pairs with minimal inter-class variation (for instance, Curly-Coated Retrievers and American Water Spaniels).
| Curly-Coated Retriever | American Water Spaniel |
|---|---|
 |
 |
Likewise, recall that labradors come in yellow, chocolate, and black.
| Yellow Labrador | Chocolate Labrador | Black Labrador |
|---|---|---|
 |
 |
 |
We also mention that random chance presents an exceptionally low bar: setting aside the fact that the classes are slightly imabalanced, a random guess will provide a correct answer roughly 1 in 133 times, which corresponds to an accuracy of less than 1%.
Pre-process the Data¶
We rescale the images by dividing every pixel in every image by 255.
from PIL import ImageFile
ImageFile.LOAD_TRUNCATED_IMAGES = True
# pre-process the data for Keras
train_tensors = paths_to_tensor(train_files).astype('float32')/255
valid_tensors = paths_to_tensor(valid_files).astype('float32')/255
test_tensors = paths_to_tensor(test_files).astype('float32')/255
(IMPLEMENTATION) Model Architecture¶
Create a CNN to classify dog breed. At the end of your code cell block, summarize the layers of your model by executing the line:
model.summary()
We have imported some Python modules to get you started, but feel free to import as many modules as you need. If you end up getting stuck, here's a hint that specifies a model that trains relatively fast on CPU and attains >1% test accuracy in 5 epochs:

As already outlined before, it is very important to extract small features and train them on the data respectively. Convolutional neural networks are very useful when it comes to feature extraction. In contrast to CNNs, MLPs make use of simple one column vectors, for which we can't identify patterns in diagonal pixels for example.
A very important architectural feature is to make our features deeper, which means that you reduce width and height of the actual input image and gain more insights about the patterns via consolidating specific parts that are presented by the layer parts (depth). In the end, you use a 'Dense layer' to weigh each feature fitted to the desired output (which the back propagation does for us).
Let's go though the layers I chose for the convolutional neural network:
A Convolutional layer
- using 16
filtersthat slide through the picture, creating a depth of 16 - a
kernel_sizeof 3 which look at a range of 3x3 pixels - relu
activationto keep only positive numbers coming in - the
input_shapemirrors the data we transformed above padding= same which doesn't play a role in this case because thestrideis set to 1 (1 step of the filter)- basically it tells us when the filter gets ahead of the border of the image, you fill in zeros for the part that goes beyond the borders
Let's quickly revise how a filter works to get a visual understanding of it

By Michael Plotke - Own work, CC BY-SA 3.0, Link
- using 16

- A Max Pooling layer
pool_sizeof 2 which means that another filter slides over the image (after the 1st layer) and takes the highest number out of the 2x2 window it uses- this way we lower the width and height which has been our goal
- it still keeps the depth, the convolutional layer created before
 Source: https://www.superdatascience.com/convolutional-neural-networks-cnn-step-2-max-pooling/
Source: https://www.superdatascience.com/convolutional-neural-networks-cnn-step-2-max-pooling/
- Another convolutional layer & Max Pooling Layer
- Conv. layer: The
filtersand thekernel_sizeare increased to increase depth and decrease width x height not as much - Max Pooling Layer: We again decrease the dimensions of width and height by 2
- Conv. layer: The
- Global Average Pooling
- We use the pooling layer to create a flatten data vector which values are the average of each of the layers' remaining numbers
- That way we can weight each of the features the model has learned to predict the class (dog breed in this case)
 Source: https://alexisbcook.github.io/2017/global-average-pooling-layers-for-object-localization/
Source: https://alexisbcook.github.io/2017/global-average-pooling-layers-for-object-localization/
- Dense Layer
- This one takes in the inputs of the weighted features and returns the probabilities of each dog breed by using a softmax activation function
- We have 133 possible dog breeds so we use this number for the neurons
 Source: https://www.learnopencv.com/image-classification-using-convolutional-neural-networks-in-keras/
Source: https://www.learnopencv.com/image-classification-using-convolutional-neural-networks-in-keras/
All in all, I was inspired by the example architecture above and just tried some different parameters. What I thought was most important, was the number of features we ask the convolutional neural network to find out. I constructed the architecture to be able to find 64 different features about each dog breed. That's why I think this model works pretty well - at least better than I would do ;)
In case of unlimited computing power and time¶
If I had unlimited computing power and time, I would try the following:
- Add another convolutional layer to extract even more abstract features from the pictures
- The more layers we have, the higher the chance of overfitting; Prevention techniques e.g.:
- Dropout layers
- Regularization (L1 / L2)
- Data Augmentation to have more data to train the network with
from keras.layers import Conv2D, MaxPooling2D, GlobalAveragePooling2D
from keras.layers import Dropout, Flatten, Dense
from keras.models import Sequential
model = Sequential()
model.add(Conv2D(filters=16, kernel_size=3, padding='same',
activation='relu', input_shape=(224, 224, 3)))
model.add(MaxPooling2D(pool_size=2, padding='valid'))
model.add(Conv2D(filters=32, kernel_size=2, padding='same',
activation='relu'))
model.add(MaxPooling2D(pool_size=2, padding='valid'))
model.add(Conv2D(filters=64, kernel_size=2, padding='same',
activation='relu'))
model.add(GlobalAveragePooling2D())
model.add(Dense(133, activation='softmax'))
model.summary()
Compile the Model¶
model.compile(optimizer='rmsprop', loss='categorical_crossentropy', metrics=['accuracy'])
Train the Model¶
from keras.callbacks import ModelCheckpoint
### TODO: specify the number of epochs that you would like to use to train the model.
epochs = 50
### Do NOT modify the code below this line.
checkpointer = ModelCheckpoint(filepath='saved_models/weights.best.from_scratch.hdf5',
verbose=1, save_best_only=True)
model.fit(train_tensors, train_targets,
validation_data=(valid_tensors, valid_targets),
epochs=epochs, batch_size=20, callbacks=[checkpointer], verbose=1)
Load the Model with the Best Validation Loss¶
model.load_weights('saved_models/weights.best.from_scratch.hdf5')
Test the Model¶
# get index of predicted dog breed for each image in test set
dog_breed_predictions = [np.argmax(model.predict(np.expand_dims(tensor, axis=0))) for tensor in test_tensors]
# report test accuracy
test_accuracy = 100*np.sum(np.array(dog_breed_predictions)==np.argmax(test_targets, axis=1))/len(dog_breed_predictions)
print('Test accuracy: %.4f%%' % test_accuracy)
bottleneck_features = np.load('/data/bottleneck_features/DogVGG16Data.npz')
train_VGG16 = bottleneck_features['train']
valid_VGG16 = bottleneck_features['valid']
test_VGG16 = bottleneck_features['test']
Model Architecture¶
The model uses the the pre-trained VGG-16 model as a fixed feature extractor, where the last convolutional output of VGG-16 is fed as input to our model. We only add a global average pooling layer and a fully connected layer, where the latter contains one node for each dog category and is equipped with a softmax.
VGG16_model = Sequential()
VGG16_model.add(GlobalAveragePooling2D(input_shape=train_VGG16.shape[1:]))
VGG16_model.add(Dense(133, activation='softmax'))
VGG16_model.summary()
Compile the Model¶
VGG16_model.compile(loss='categorical_crossentropy', optimizer='rmsprop', metrics=['accuracy'])
Train the Model¶
checkpointer = ModelCheckpoint(filepath='saved_models/weights.best.VGG16.hdf5',
verbose=1, save_best_only=True)
VGG16_model.fit(train_VGG16, train_targets,
validation_data=(valid_VGG16, valid_targets),
epochs=20, batch_size=20, callbacks=[checkpointer], verbose=1)
Load the Model with the Best Validation Loss¶
VGG16_model.load_weights('saved_models/weights.best.VGG16.hdf5')
Test the Model¶
Now, we can use the CNN to test how well it identifies breed within our test dataset of dog images. We print the test accuracy below.
# get index of predicted dog breed for each image in test set
VGG16_predictions = [np.argmax(VGG16_model.predict(np.expand_dims(feature, axis=0))) for feature in test_VGG16]
# report test accuracy
test_accuracy = 100*np.sum(np.array(VGG16_predictions)==np.argmax(test_targets, axis=1))/len(VGG16_predictions)
print('Test accuracy: %.4f%%' % test_accuracy)
Predict Dog Breed with the Model¶
from extract_bottleneck_features import *
def VGG16_predict_breed(img_path):
# extract bottleneck features
bottleneck_feature = extract_VGG16(path_to_tensor(img_path))
# obtain predicted vector
predicted_vector = VGG16_model.predict(bottleneck_feature)
# return dog breed that is predicted by the model
return dog_names[np.argmax(predicted_vector)]
Step 5: Create a CNN to Classify Dog Breeds (using Transfer Learning)¶
In Step 4, we used transfer learning to create a CNN using VGG-16 bottleneck features. In this section, we must use the bottleneck features from a different pre-trained model. To make things easier, the features are pre-computed for all of the networks that are currently available in Keras. These are already in the workspace, at /data/bottleneck_features.
The files are encoded as such:
Dog{network}Data.npz
where {network}, in the above filename, can be one of VGG19, Resnet50, InceptionV3, or Xception.
The above architectures are downloaded and stored for you in the /data/bottleneck_features/ folder.
This means the following will be in the /data/bottleneck_features/ folder:
DogVGG19Data.npz
DogResnet50Data.npz
DogInceptionV3Data.npz
DogXceptionData.npz
Obtain Bottleneck Features¶
In the code block below, we extract the bottleneck features corresponding to the train, test, and validation sets by running the following:
bottleneck_features = np.load('/data/bottleneck_features/Dog{network}Data.npz')
train_{network} = bottleneck_features['train']
valid_{network} = bottleneck_features['valid']
test_{network} = bottleneck_features['test']### TODO: Obtain bottleneck features from another pre-trained CNN.
bottleneck_features_VGG19 = np.load('/data/bottleneck_features/DogVGG19Data.npz')
train_VGG19 = bottleneck_features_VGG19['train']
valid_VGG19 = bottleneck_features_VGG19['valid']
test_VGG19 = bottleneck_features_VGG19['test']
### TODO: Obtain bottleneck features from another pre-trained CNN.
bottleneck_features_Resnet50 = np.load('/data/bottleneck_features/DogResnet50Data.npz')
train_Resnet50 = bottleneck_features_Resnet50['train']
valid_Resnet50 = bottleneck_features_Resnet50['valid']
test_Resnet50 = bottleneck_features_Resnet50['test']
### TODO: Obtain bottleneck features from another pre-trained CNN.
bottleneck_features_InceptionV3 = np.load('/data/bottleneck_features/DogInceptionV3Data.npz')
train_InceptionV3 = bottleneck_features_InceptionV3['train']
valid_InceptionV3 = bottleneck_features_InceptionV3['valid']
test_InceptionV3 = bottleneck_features_InceptionV3['test']
### TODO: Obtain bottleneck features from another pre-trained CNN.
bottleneck_features_Xception = np.load('/data/bottleneck_features/DogXceptionData.npz')
train_Xception = bottleneck_features_Xception['train']
valid_Xception = bottleneck_features_Xception['valid']
test_Xception = bottleneck_features_Xception['test']
Model Architecture¶
- At first, I loaded the bottleneck features for all of the four pre-trained CNNs
- Secondly, I created the four models and added a Dense layer representing each breed
- Thirdly, I compiled the model with the suited optimizers and the
accuracymetric - The model is then trained to fit the bottleneck features to each breed given by the labelled data
- I then get four different results for accuracy for the validation data which you will see in the training epochs yourself:
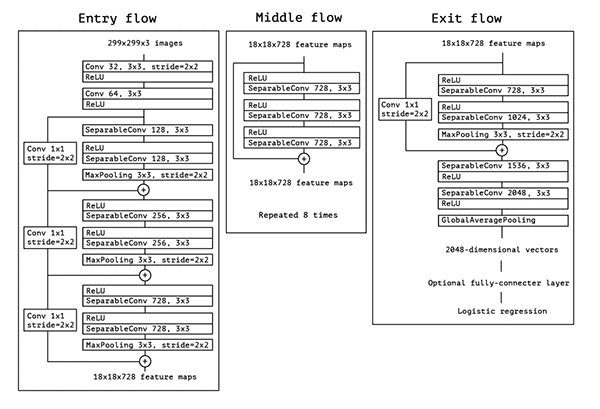
- Choosing the best suited model: I chose Xception with an overall accuracy of 84.6890% on the test dataset
Why is Xception a great choice for our data?
At first, I want to mention that all of these models have been trained on the ImageNet dataset which has been described earlier. Xception is built upon the idea of inceptions (which were introduced by the Inception model which is Google's work). Inceptions. I found this great article about inceptions on medium (https://towardsdatascience.com/a-simple-guide-to-the-versions-of-the-inception-network-7fc52b863202):
The Premise: Salient parts in the image can have extremely large variation in size. Shown here:
 From left: A dog occupying most of the image, a dog occupying a part of it, and a dog occupying very little space (Images obtained from Unsplash).
From left: A dog occupying most of the image, a dog occupying a part of it, and a dog occupying very little space (Images obtained from Unsplash).
- Because of this huge variation in the location of the information, choosing the right kernel size for the convolution operation becomes tough. A larger kernel is preferred for information that is distributed more globally, and a smaller kernel is preferred for information that is distributed more locally.
- Very deep networks are prone to overfitting.
- It also hard to pass gradient updates through the entire network.
- Naively stacking large convolution operations is computationally expensive.
The Solution: Why not have filters with multiple sizes operate on the same level? The network essentially would get a bit “wider” rather than “deeper”. The authors designed the inception module to reflect the same.
The below image is the “naive” inception module. It performs convolution on an input, with 3 different sizes of filters (1x1, 3x3, 5x5). Additionally, max pooling is also performed. The outputs are concatenated and sent to the next inception module.
This way, we gather more information in a more efficient way. This works well for our dataset, because the pictures vary in a lot of ways (like explained above). So we can improve the feature extraction with this model.
That's how the architecture of the Xception CNN works:
VGG-19 model¶
### TODO: Define your architecture.
VGG19_model = Sequential()
VGG19_model.add(GlobalAveragePooling2D(input_shape=train_VGG19.shape[1:]))
VGG19_model.add(Dense(133, activation='softmax'))
VGG19_model.summary()
ResNet 50¶
### TODO: Define your architecture.
Resnet50_model = Sequential()
Resnet50_model.add(GlobalAveragePooling2D(input_shape=train_Resnet50.shape[1:]))
Resnet50_model.add(Dense(133, activation='softmax'))
Resnet50_model.summary()
Inception V3¶
### TODO: Define your architecture.
InceptionV3_model = Sequential()
InceptionV3_model.add(GlobalAveragePooling2D(input_shape=train_InceptionV3.shape[1:]))
InceptionV3_model.add(Dense(133, activation='softmax'))
InceptionV3_model.summary()
Xception¶
### TODO: Define your architecture.
Xception_model = Sequential()
Xception_model.add(GlobalAveragePooling2D(input_shape=train_Xception.shape[1:]))
Xception_model.add(Dense(133, activation='softmax'))
Xception_model.summary()
(IMPLEMENTATION) Compile the Model¶
VGG-19¶
### TODO: Compile the model.
VGG19_model.compile(loss='categorical_crossentropy', optimizer='rmsprop', metrics=['accuracy'])
Resnet50_model.compile(loss='categorical_crossentropy', optimizer='rmsprop', metrics=['accuracy'])
InceptionV3_model.compile(loss='categorical_crossentropy', optimizer='rmsprop', metrics=['accuracy'])
Xception_model.compile(loss='categorical_crossentropy', optimizer='rmsprop', metrics=['accuracy'])
Train the Model¶
### TODO: Train the model.
checkpointer = ModelCheckpoint(filepath='saved_models/weights.best.VGG19.hdf5',
verbose=1, save_best_only=True)
VGG19_model.fit(train_VGG19, train_targets,
validation_data=(valid_VGG19, valid_targets),
epochs=20, batch_size=20, callbacks=[checkpointer], verbose=1)
### TODO: Train the model.
checkpointer = ModelCheckpoint(filepath='saved_models/weights.best.Resnet50.hdf5',
verbose=1, save_best_only=True)
Resnet50_model.fit(train_Resnet50, train_targets,
validation_data=(valid_Resnet50, valid_targets),
epochs=20, batch_size=20, callbacks=[checkpointer], verbose=1)
### TODO: Train the model.
checkpointer = ModelCheckpoint(filepath='saved_models/weights.best.InceptionV3.hdf5',
verbose=1, save_best_only=True)
InceptionV3_model.fit(train_InceptionV3, train_targets,
validation_data=(valid_InceptionV3, valid_targets),
epochs=20, batch_size=20, callbacks=[checkpointer], verbose=1)
### TODO: Train the model.
checkpointer = ModelCheckpoint(filepath='saved_models/weights.best.Xception.hdf5',
verbose=1, save_best_only=True)
Xception_model.fit(train_Xception, train_targets,
validation_data=(valid_Xception, valid_targets),
epochs=20, batch_size=20, callbacks=[checkpointer], verbose=1)
Load the Model with the Best Validation Loss¶
### TODO: Load the model weights with the best validation loss.
Xception_model.load_weights('saved_models/weights.best.Xception.hdf5')
Test the Model¶
# get index of predicted dog breed for each image in test set
Xception_predictions = [np.argmax(Xception_model.predict(np.expand_dims(feature, axis=0))) for feature in test_Xception]
# report test accuracy
test_accuracy = 100*np.sum(np.array(Xception_predictions)==np.argmax(test_targets, axis=1))/len(Xception_predictions)
print('Test accuracy: %.4f%%' % test_accuracy)
Predict Dog Breed with the Model¶
### TODO: Write a function that takes a path to an image as input
### and returns the dog breed that is predicted by the model.
def predict_dog_breed(img_path):
# extract bottleneck features
bottleneck_feature = extract_Xception(path_to_tensor(img_path))
# obtain predicted vector
predicted_vector = Xception_model.predict(bottleneck_feature)
# return dog breed that is predicted by the model
return dog_names[np.argmax(predicted_vector)]
Step 6: Write an Algorithm¶
We are going to write an algorithm that accepts a file path to an image and first determines whether the image contains a human, dog, or neither. Then,
- if a dog is detected in the image, return the predicted breed.
- if a human is detected in the image, return the resembling dog breed.
- if neither is detected in the image, provide output that indicates an error.
Write our Algorithm¶
import time
import matplotlib.image as mpimg
def print_after_sleep(txt,sec,end=''):
time.sleep(sec)
print(txt, end = end)
def my_algorithm(image):
# probability for being human / dog
human = face_detector(image)
dog = dog_detector(image)
dog_breed = predict_dog_breed(image).split(".")[1].replace("_"," ")
while True:
if human and not dog:
print("Hello there!")
print_after_sleep("You seem to be of human race. Let's investigate your potential dog breed though",1,end='')
print_after_sleep(".",1,end='')
print_after_sleep(".",1,end='')
print_after_sleep(".",1,end='\n')
print_after_sleep("I found out! It would be {}".format(dog_breed),1,end='\n')
break
elif (human and dog) or (not human and not dog):
print("Hello there!")
print_after_sleep("You don't seem to be a human or a dog. I'm not quite sure what kind of thing you are",1,end='')
print_after_sleep(".",1,end='')
print_after_sleep(".",1,end='')
print_after_sleep(".",1,end='\n')
print_after_sleep("I found out! You must be a human {}".format(dog_breed),1,end='\n')
break
elif dog and not human:
print("Hello there!")
print_after_sleep("You don't seem to be human",1,end='')
print_after_sleep(".",1,end='')
print_after_sleep(".",1,end='')
print_after_sleep(".",1,end='\n')
print_after_sleep("Ha! You are a {}".format(dog_breed),1,end='\n')
break
else:
break
print_after_sleep("This is what I got as image: ".format(dog_breed),1,end='\n\n\n')
img = mpimg.imread(image)
plt.imshow(img)
imgs = ["images/sunny1.JPG","images/sunny2.JPG","images/sunny3.JPG", "images/orisha.jpeg", "images/random.jpeg", "images/myself.JPG", "images/girl.jpg"]
my_algorithm(imgs[0])

my_algorithm(imgs[1])

my_algorithm(imgs[2])

my_algorithm(imgs[3])

my_algorithm(imgs[4])

my_algorithm(imgs[5])

Unfortunately, the algorithm doesn't do as well as expected. My dog was classified as human chihuahua twice and got once labelled as a Finnish Spitz. The fact that my dog is a mix of pinscher and spitz makes it pretty hard for the model to correctly tell us what dog breed it has.
Adding a breed for my dog: Adding another breed that would match would only partially solve the problem. The more breeds we have the more features the model would have to fit to the data.
Using data augmentation to provide more training dasta for each breed: Data Augmentation is a way that increases the variance of pictures. There might be positional aspects the model takes into account which we could lower the impact of. Data Augmentation uses shifts and rotations as well as changing colors (to black and white for example) or lightings or other methods to provide data that has more variance. This would only be usable if the model is built from scratch.
Data Augmentation in action:
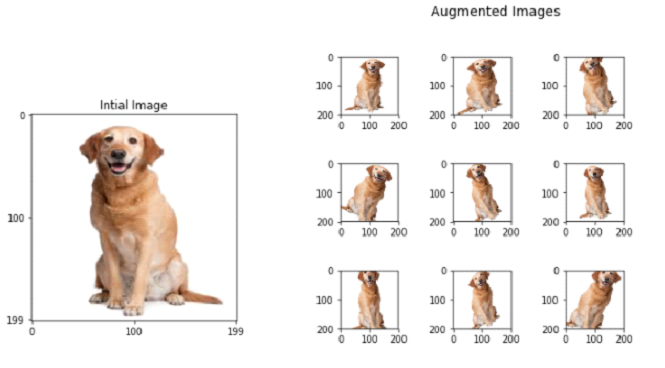 Source: https://towardsdatascience.com/image-augmentation-14a0aafd0498
Source: https://towardsdatascience.com/image-augmentation-14a0aafd0498
- Epochs and batch sizes: The batch size defines the gradient and how often to update weights. An epoch is the entire training data exposed to the network, batch-by-batch. Small batch sizes with large epoch size and a large number of training epochs are common in modern deep learning implementations. This may or may not hold with the problem. E.g.:
- Try batch size equal to training data size, memory depending (batch learning).
- Try a batch size of one (online learning).
- Try a grid search of different mini-batch sizes (8, 16, 32, …).
- Try training for a few epochs and for a heck of a lot of epochs. This would require more time for training and finding the right parameters that are best suited for the model we're training.
Source: https://www.quora.com/What-is-an-epoch-in-deep-learning