Job Offer Scraping¶
![]()
Our mission¶
The mission is to automate job applications for everybody.
Pre-done work¶
I wrote a web-crawler in python to get job description from a German website called https://www.stepstone.de. I did the following step:
- Crawling all the links pointing on sites that show job offers. I built an algorithm that crawls through different pages covering specific industries where jobs are offered
What this notebook covers¶
In this notebook, the goal is to extract the needed information out of the job offers on the platform. We will then use the extracted data for further investigation, especially building Machine Learning models on top of the high quality data.
Steps¶
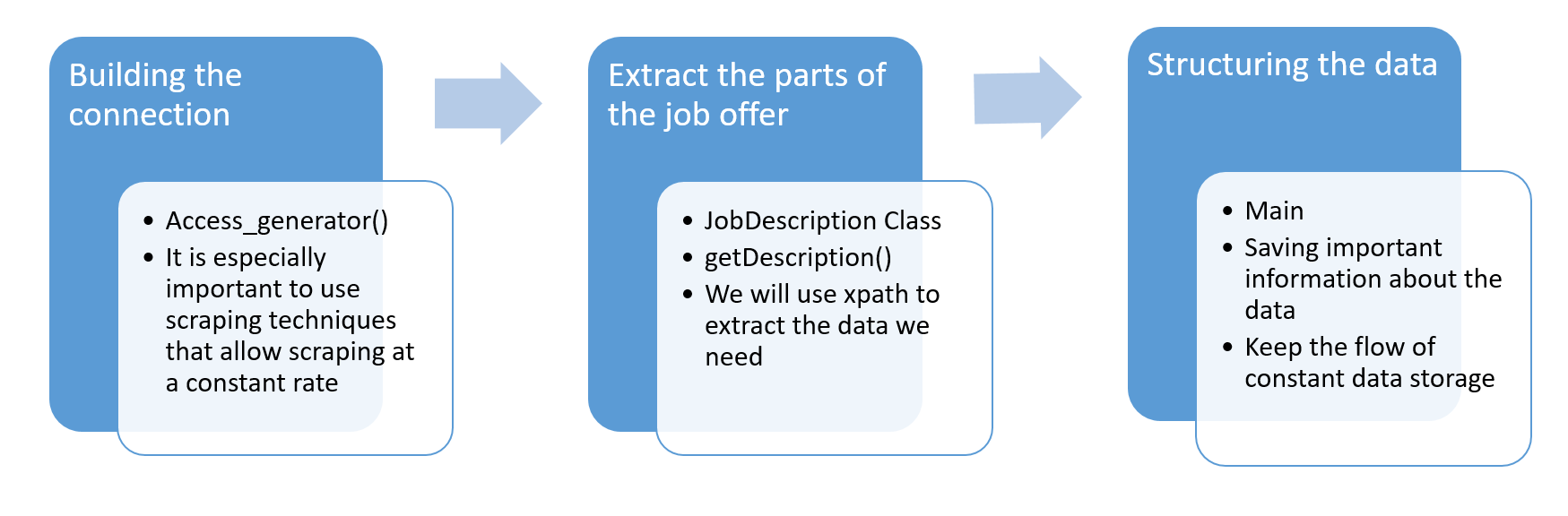
Making imports¶
At first, we need to import the libraries and tools (incl. model) we need to start.
from lxml import html
from lxml import etree
import requests
import pandas as pd
import time
import json
import random
1. Defining useful variables¶
User Agents¶
A user agent is a string that a browser or app sends to each website you visit. A typical user agent string contains details like – the application type, operating system, software vendor or software version of the requesting software user agent. Web servers use this data to assess the capabilities of your computer, optimizing a page’s performance and display. User Agents are sent as a request header called “User-Agent”. (https://www.scrapehero.com/how-to-fake-and-rotate-user-agents-using-python-3/)
In this case, we want to define User Agents to not be noticed that easily. It's not a great way to stay anonymous, because the website we scrape from still notices our IP address (which I will show a solution for as well). But, we want to try anything that increases our chance of getting more data.
USER_AGENTS = [
('Mozilla/5.0 (X11; Linux x86_64) '
'AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/57.0.2987.110 '
'Safari/537.36'), # chrome
('Mozilla/5.0 (X11; Linux x86_64) '
'AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/61.0.3163.79 '
'Safari/537.36'), # chrome
('Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:55.0) '
'Gecko/20100101 '
'Firefox/55.0'), # firefox
('Mozilla/5.0 (X11; Linux x86_64) '
'AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/61.0.3163.91 '
'Safari/537.36'), # chrome
('Mozilla/5.0 (X11; Linux x86_64) '
'AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/62.0.3202.89 '
'Safari/537.36'), # chrome
('Mozilla/5.0 (X11; Linux x86_64) '
'AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/63.0.3239.108 '
'Safari/537.36'), # chrome
]
Intitialization variable¶
In the future, we will use this scraper as a python script that we want to call anywhere. I'm defining an INITIALIZATION variable to know which parameters we can change for our scraper. This is also a good way to make the whole program clearer for a third person. Descriptions for each parameter is giving inside the code.
INITIALIZATION = {
# how many requests the scraper makes before stopping
"max_requests": 1000,
# how many successful requests are possible?
"max_successful_requests": 500,
# saving every ..th phase
"saving_frequency": 5,
# when does the scraper stop trying when not working?
"scraper_stop": (2+len(USER_AGENTS))
}
Reporting variable¶
This reporting variable contains the most important information about the scraper's errors that arrived. It also stores the use of different methods we use for being invisible for the admins of the website (which can be a problem when getting too much information). It stores the time the scraper processes and gives us the number of job offers we got from a scraping period.
_reporting = {
# errors/breaks
"breaks_from_already_used_urls": 0,
"breaks_from_broken_scraping_technique": 0,
"breaks_from_ended_page": 0,
"breaks_from_unsimilar_rows": 0,
"breaks_from_wrong_format": 0,
"breaks_from_wrong_format_for_texts": 0,
"saving_error": 0,
"error_messages": [],
# new scraping data in form of jobs
"new_jobs_total": 0,
# scraping techniques
"traditional_request": 0,
"proxycrawl": 0,
"scraper_api": 0,
# time for processing
"starting_time": 0, #in seconds
"ending_time": 0, #in seconds
"total_time": 0 #in minutes
}
2. Defining useful functions¶
Scraper functions¶
At first, we can catch a scraping error by looking for specific HTML elements that pop up when the admin caught us downloading too much data. The scraper_works function looks for a captcha box that is required when the website suspects that you automatically route through it.
def scraper_works(page):
tree = html.fromstring(page)
if tree.xpath("//div[@id='captcha-box']"):
return False
else:
return True
The access_generator is the function that actually downloads the page you are looking for. It is designed to avoid traps, to randomly select a User Agent and to randomly select a scraping metod when the traditional way doesn't work for the particular purpose. Info: I Xed out the API tokens I got from proxycrawl and scraperapi
#Proxycrawl, ScraperAPI
status = [True,True]
def access_generator(link, access_type = 1, nr = 0):
nr += 1
print("Attempt No. {}".format(nr))
# randomly choose a user agent
headers = {'User-Agent': USER_AGENTS[round(random.random())*(len(USER_AGENTS)-1)]}
# stop scraper after a number of attempts
if nr > INITIALIZATION["scraper_stop"]:
return None
if access_type == 1:
page = requests.get(link, headers = headers)
if page.status_code == 200 and scraper_works(page.content):
_reporting["traditional_request"] += 1
return html.fromstring(page.content)
else:
return access_generator(link, 2, nr)
if access_type == 2:
if status[0] and not status[1]:
proxy_rotator = 0
elif status[1] and not status[0]:
proxy_rotator = 1
else:
# randomly selecting proxy rotator
proxy_rotator = round(random.random())
if proxy_rotator == 0:
page = requests.get('https://api.proxycrawl.com/?token=TOKEN_ID&format=html&url=' + link)#,headers=headers)
result = page.content
_reporting["proxycrawl"] += 1
if page.status_code == 429:
status[0] = False
else:
payload = {'key': 'KEY', 'url':link}
page = requests.get('http://api.scraperapi.com', params=payload)
_reporting["scraper_api"] += 1
if page.status_code == 429:
status[1] = False
# Return page if successfully loaded
if page.status_code == 200 and scraper_works(page.content):
return html.fromstring(page.content)
else:
return access_generator(link, 2, nr)
return None
Handy tools¶
I built 4 functions with the purpose of decreasing the lines of code of the main function. already_used checks if a specific URL has already been used, clear_link cuts off irrelevant parts of the URL for further crawling, saveDf and saveAll are functions to store the scraped data.
def already_used(l):
if l in already_used_urls:
print("url ALREADY used!")
return True
else:
return False
def clear_link(link):
l = link.split("?")[0]
return l
def saveDf(df, name):
df = df.drop_duplicates()
df.to_csv(name)
print("Saved: {}".format(df.info()))
def saveAll():
used_urls = pd.DataFrame({'urls':already_used_urls}).drop_duplicates()
saveDf(used_urls,"used_urls.csv")
jo_json = job_offers.to_json()
with open('job_offers.json', 'w') as outfile:
json.dump(jo_json, outfile)
3. Defining a class to work with the data¶
This class JobDescription has the intention to make the data more clearly. It contains all the information a job offer can possibly have for us and has integrated methods to structure the data for us. It also gives us information about how much information we have about a specific job (getCompleteness).
class JobDescription():
def __init__(self,company,job_name,location,url,department,headlines,text,address,employment_type,working_hours,completeness,htmls):
self.company = company
self.job_name = job_name
self.location = location
self.url = url
self.department = department
self.headlines = headlines
self.text = text
self.address = address
self.employment_type = employment_type
self.working_hours = working_hours
self.completeness = completeness
self.htmls = htmls
def __str__(self):
return str(self.__class__) + ": " + str(self.__dict__)
def getCompleteness(self):
v = 0.0
for b in self.completeness:
if b == True:
v += 1/len(self.completeness)
return round(v*100)
def getTextAsDataSet(self):
return pd.DataFrame({
"headline": self.headlines,
"text": self.text
})
def makeDF(self):
if self.text != [""]:
return pd.DataFrame({
"job_name": [self.job_name],
"company": [self.company],
"location": [self.location],
"url": [self.url],
"headlines": [self.headlines],
"text": [self.text],
"address": [self.address],
"employment_type": [self.employment_type],
"working_hours": [self.working_hours],
"htmls": [self.htmls]
})
else:
return None
4. Extracting the data¶
getDescription is all about extracting data out of raw html, we get from access_generator. We catch all the errors that come across and finally hand the data over to a JobDescription object which we return.
def getDescription(name,company,location,url,department):
complete = [False,False,False,False,False,False]
if already_used(url):
_reporting["breaks_from_already_used_urls"]+=1
return False
print("Link: {}".format(url))
tree = access_generator(url)
if not tree:
_reporting["breaks_from_broken_scraping_technique"]+=1
return False
divs = tree.xpath("//div[@class='card__body']")
headlines = []
texts = []
htmls = []
if len(divs) == 0:
_reporting["breaks_from_wrong_format"]+=1
return False
## iterate through divs
for d in divs:
htmls.append(etree.tostring(d, pretty_print=True, method="html"))
complete[0] = True
h2 = [h2 for h2 in d.xpath("h2")]
if len(h2)>0:
headlines.append(h2[0].text_content())
else:
headlines.append("")
if len(headlines) > 1:
complete[1] = True
try:
texts.append("".join(d.xpath("div")[0].text_content()))
if len(texts) > 0:
complete[2] = True
except Exception as inst:
_reporting["error_messages"].append(str(inst))
_reporting["breaks_from_wrong_format_for_texts"]+=1
return False
## address
address = tree.xpath("//address[@class='richtext']/text()")
if address:
complete[3] = True
## employment_type (unlimited time, limited time)
employment_type = ""
try:
employment_type = [art for art in tree.xpath("//li[@class='listing-list at-listing__list-icons_contract-type']/text()")][1]
complete[4] = True
except:
pass
## working time (full/part time)
working_hours = ""
try:
working_hours = [art for art in tree.xpath("//li[@class='listing-list at-listing__list-icons_work-type']/text()")][1]
complete[5] = True
except:
pass
return JobDescription(company,name,location,url,department,headlines,texts,address,employment_type,working_hours,complete,htmls)
5. Scraping¶
Now, the scraping can begin. We're reading in the data we already scraped before and using the parameters to get the machinery started. The main points to emphasize are the following:
- We have a hard and a oft ending, which means that we have a maximum for successful requests and a global maximum where the scraper stops immediately. This is because the data set might be full of dead links so the global maximum prevents our request limit to exceed, both for the APIs and the website. Because at some number, your IP eventually suffers from being banned by the server.
- This program automatically saves the dataset so we don't lose information we gathered. Though, you must make sure, that the
saving_frequencyvalue is a divisor of bothmax_requestvariables. Otherwise, we might lose information in the last epochs.
_reporting["starting_time"] = time.time()
already_used_urls = []
try:
jobs_df = pd.read_csv("../categorized_jobs.csv",index_col = 0)
with open('job_offers.json', 'r') as outfile:
job_offers_json = json.load(outfile)
job_offers = pd.read_json(job_offers_json)
used_urls = pd.read_csv("used_urls.csv")
already_used_urls = used_urls["urls"].tolist()
except Exception as inst:
_reporting["error_messages"].append(str(inst))
print("Not working... Wrong file?")
counter = 0
HARD_ENDING = INITIALIZATION["max_requests"]
SOFT_ENDING = INITIALIZATION["max_successful_requests"]
# iterate through the job links and save each job description JobDescription-object
for index, row in jobs_df[:HARD_ENDING].iterrows():
if counter >= SOFT_ENDING:
print("Scraper ended...")
break
#name,company,location,url,department
name = row["Name"]
company = row["Company"]
location = row["Location"]
url = row["URL"]
department = row["Department"]
# get the job offer
result = getDescription(name,company,location,url,department)
# check if worked
if result == False:
print("No result!")
continue
# append it to the dataframe
job_offers = job_offers.append(result.makeDF(),ignore_index = True)
already_used_urls.append(url)
# activate counters
counter += 1
_reporting["new_jobs_total"] += 1
if counter % INITIALIZATION["saving_frequency"] == 0:
try:
saveAll()
except Exception as inst:
_reporting["error_messages"].append(str(inst))
_reporting["saving_error"] += 1
HARD_ENDING = counter
break
try:
saveAll()
except Exception as inst:
_reporting["error_messages"].append(str(inst))
_reporting["saving_error"] += 1
_reporting["ending_time"] = time.time()
_reporting["total_time"] = (_reporting["ending_time"] - _reporting["starting_time"]) / 60 #in minutes
6. Further analysis¶
In the following, the reporting variable and the final dataset is printed. That way we can directly see the success our scraper had. For further analysis, please look at my website. On the one hand, I trained a Machine Learning model to predict a sentence's role in a job offer and on the other hand, I used Deep Learning techniques to receive further information from each job offer we scraped here.
_reporting
job_offers.head(10)