General Text Preprocessing¶
![]()
Our mission¶
The mission is to automate job applications for everybody.
Pre-done work¶
I already did the following steps:
- Crawling all the links pointing on sites that show job offers
- Scraping each job offer with all information available
- Job name
- Company and link to its description site
- Job type (part-time/full-time/freelance etc.)
- Description (Stepstone uses html-parts to divide each section of the job offer)
- Saving all of the divided descriptions in a DataFrame (pandas)
- 1st column: headline
- 2nd column: text
- Cleaning the data
- Reducing the labels from about 5000 to 5 so that we have the following labels:
- company: a description of the company ("About us"-page)
- tasks: a description of the job offered (especially the tasks of the job)
- profile: a description of the skills needed to fulfill the job's requirements ("Your profile")
- offer: a description of what the company offers for the applicant ("What to expect", "What we offer to you")
- contact: contact details for the applicant (also including a hint whom to adress in the application)
- Reducing the labels from about 5000 to 5 so that we have the following labels:
- NOW: Preprocessing Pipeline
- The goal is to be able to handle text in different dimensionality, meaning that any lists of text, no matter what depth the list has, should be handled and returned in the desired format. For example:
['Hello, this is an example', ['Let's see if I get encrypted']][[['Hello, this is an example'], ['Let's see if I get encrypted']]]
- Operations with text can be at lower level, e.g. removing punctuation, but higher level as well, such as removing stop words or chaining words together.
- Also, emojis can be handled and even edited to represent a specific mood of the author
- The goal is to be able to handle text in different dimensionality, meaning that any lists of text, no matter what depth the list has, should be handled and returned in the desired format. For example:
What this notebook covers¶
In this notebook, I'm going to explain different techniques and present a pipeline that can be used for different type of text to either classify it or extract information out of it.
The data we use¶
We use a dataframe which I scraped from www.stepstone.de. The scraping process is in a separate jupyter notebook.
Pipeline¶
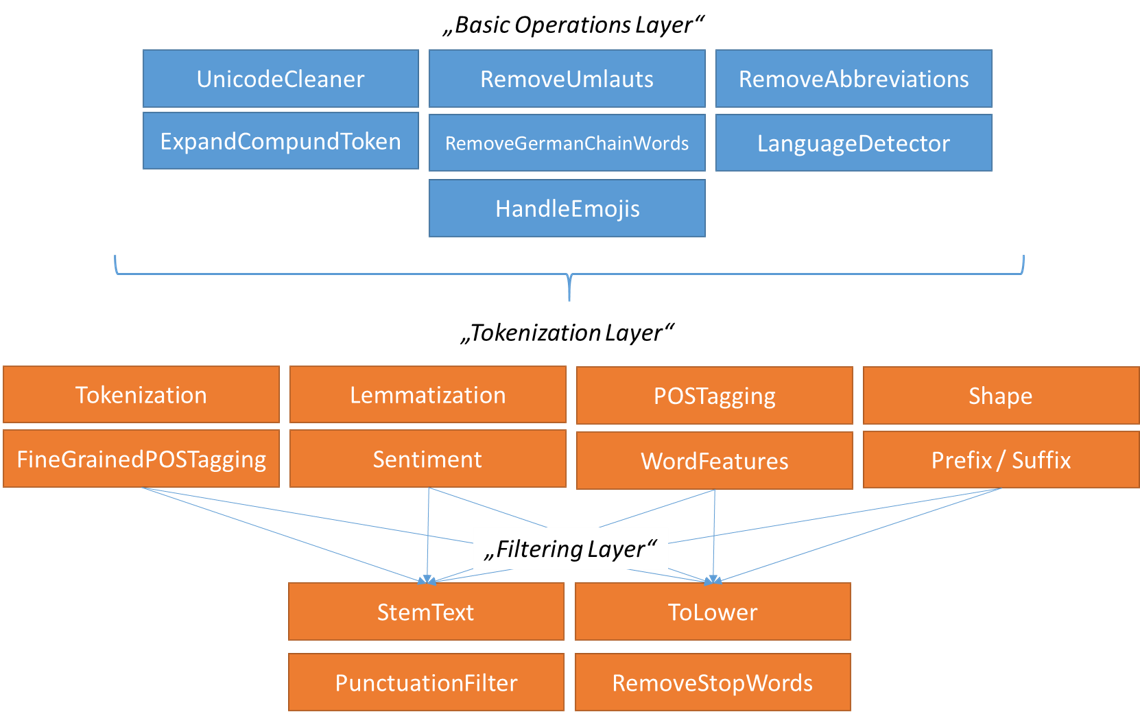
For this case, we are assigning labels for each of the layers:
level 1: “Basic Operation Layer“level 2: “Tokenization Layer“level 3: “Filtering Layer“
Making imports¶
At first, we need to import the libraries and tools (incl. model) we need to start.
#import spacy
#from spacy.tokenizer import Tokenizer
#from spacy.lemmatizer import Lemmatizer
import char_split
import re
import string
import json
import io
import spacy
import copy
nlp = spacy.load('de_core_news_sm')
#tokenizer = Tokenizer(nlp.vocab)
Useful generator function to reduce dimensionality¶
To be able to serve preprocessed documents in various forms regarding dimensionality, we provide the orchestrator with different generators to serve only strings. This is because our defined functions will either preprocess a string or a list of tokens. Here are examples for how differently lists can be structured:
['Hello, this is an example', ['Let's see if I get encrypted']][[['Hello, this is an example'], ['Let's see if I get encrypted']]]
The depth_calculator and countMultiDimensionalList provide us information of how a list is structured, whereas iterate_Strings and iterateStringsWithPosition helps us to only yield the strings to our preproccing functions.
depth = lambda L: isinstance(L, list) and max(map(depth, L))+1
def depth_calculator(L):
if isinstance(L, list) and len(L) > 0:
return max(map(depth_calculator, L))+1
return 0
def iterateStrings(list_,nr):
if nr > 1:
for x in list_:
yield from iterateStrings(copy.copy(x),nr-1)
else:
if type(list_) == list or type(list_) == tuple:
for x in list_:
yield copy.copy(x)
else:
yield copy.copy(list_)
def countMultidimensionalList(list_):
if type(list_) == list:
return sum(countMultidimensionalList(subitem) for subitem in list_)
else:
return 1
def iterateStringsWithPosition(list_,nr,m,position=[]):
pos = []
if len(position) == 0:
pos = [0]*m
else:
pos = position
if nr > 1:
for idx,x in enumerate(list_):
pos[m-nr] = idx
yield from iterateStringsWithPosition(copy.copy(x),nr-1,m,pos)
else:
if type(list_) == list:
for idx,x in enumerate(list_):
pos[-1] = idx
yield copy.copy(x),pos
else:
yield list_,pos
Unicode Cleaner¶
In some strings, you find Unicode characters (especially if you use HTML data) that can influence classification results negatively. By removing these characters, we can again reduce redundancy.
By using seperator as a local boolean, we can make sure that separation strings like \n, \t or \r can be kept if wanted. This is because you sometimes might want to use this to further analyze seperation of text to gain more insights.
def unicodeCleaner(text, seperator = False):
d = text.replace(u'\xad',u'')
d = d.replace(u'\xa0', u' ')
d = d.replace(u'\xa4', u'ä')
d = d.replace(u'\xb6', u'ö')
d = d.replace(u'\xbc', u'ü')
d = d.replace(u'\xc4', u'Ä')
d = d.replace(u'\xd6', u'Ö')
d = d.replace(u'\xdc', u'Ü')
d = d.replace(u'\x9f', u'ß')
if seperator:
d = d.replace(u'\n', u'')
d = d.replace(u'\t', u'')
d = d.replace(u'\r', u'')
return d
Remove umlauts¶
In some languages - especially German - there are characters which might written in different forms some times. By changing these characters to another common form, we can reduce redundancy for strings.
def removeUmlauts(text):
res = text.replace('ä', 'ae')
res = res.replace('ö', 'oe')
res = res.replace('ü', 'ue')
res = res.replace('Ä', 'Ae')
res = res.replace('Ö', 'Oe')
res = res.replace('Ü', 'Ue')
res = res.replace('ß', 'ss')
return res
Removing chained words¶
This is a specialty of German language. We sometimes use sentences containing chain words. For example, if two words have the same ending like "Lernbereitschaft" and "Reisebereitschaft" we often use an abbreviation for the first word and chain the second word with a connection word like "und","oder","sowie" (engl. and, or, as well as).
For the preprocessing process, we want to make sure that each word is kept so we are going to use regex to make a chain out of these words. We are going to use a library called char_split that cuts the second word into two words and puts the second part of the second word at the end of the first:
Lern- Reise | bereitschaft -> Lernbereitschaft Reisebereitschaft
The chainword we'll normally use is "und" (engl. and) which doesn't change the meaning of the text drastically. If you want to make sure that everything is chained correctly you can choose your own chainword.
def charSplitting(i,groups,chainword="und"):
word1 = groups[0].replace(" ","")
word2 = groups[1].replace(" ","")
if len(groups) >= 4:
word3 = str(groups[2]).replace(" ","")
if len(groups) >= 5:
word4 = str(groups[3]).replace(" ","")
if i == 0:
#print("{}{}".format(groups[0],groups[1]),groups[1])
return "{}{} {} {}".format(word1,word2,chainword,word2)
if i == 1:
if len(word4)>1:
splitted = char_split.split_compound(word4)[0][-1].lower()
return "{}{} {} {}{} {} {}".format(word1,word3.split("-")[1],chainword,word2,word3.split("-")[1],chainword,word3)
else:
splitted = char_split.split_compound(word3)[0][-1].lower()
return "{}{} {} {}{} {} {}".format(word1,splitted,chainword,word2,splitted,chainword,word3)
if i == 2:
if len(word3)>1:
splitted = char_split.split_compound(word3)[0][-1].lower()
return "{}{} {} {}".format(word1,word2.split("-")[1],chainword,word2)
else:
splitted = char_split.split_compound(word2)[0][-1].lower()
return "{}{} {} {}".format(word1,splitted,chainword,word2)
def removeGermanChainWords(text):
regex = []
# brackets with following word: usually belonging together in german: (Wirtschafts-)Informatik, building two words
regex.append("['(']{1}([A-Za-z0-9_äÄöÖüÜß]+).[')'](.?\w+)")
# list of combined words beloning together (3)
regex.append("([A-Za-z0-9_äÄöÖüÜß]+)-[,][' ']?([A-Za-z0-9_äÄöÖüÜß]+)-[' ']?[und|oder|sowie|&|,]+[' ']([A-Za-z0-9_äÄöÖüÜß]+-?([A-Za-z0-9_äÄöÖüÜß]+))")
# brackets with following word: usually belonging together in german: lv- oder kvbestandsfuehrungssystem,
# building two words but we have to append the second part of the second word to the first word
regex.append("([A-Za-z0-9_äÄöÖüÜß]+)-[' ']?[und|oder|sowie|&]+[' ']([A-Za-z0-9_äÄöÖüÜß]+-?([A-Za-z0-9_äÄöÖüÜß]+))")
# Wirtschafts-/Informatik
regex.append("([A-Za-z0-9_äÄöÖüÜß]+)-['']?['/','&',',']['']?([A-Za-z0-9_äÄöÖüÜß]+)")
sentence = text
m = re.search(regex[0],sentence)
if m:
findings = m.groups()
for c in zip(findings[::2], findings[1::2], range(0,len(findings),2)):
sentence = sentence.replace(sentence[m.start(c[-1]):m.end(c[-1])], charSplitting(0,c))
m = re.search(regex[1],sentence)
if m:
findings = m.groups()
for c in zip(findings[::4], findings[1::4], findings[2::4], findings[3::4], range(0,len(findings),4)):
sentence = sentence.replace(sentence[m.start(c[-1]):m.end(c[-1])], charSplitting(1,c))
m = re.search(regex[2],sentence)
if m:
findings = m.groups()
for c in zip(findings[::3], findings[1::3], findings[2::3], range(0,len(findings),3)):
sentence = sentence.replace(sentence[m.start(c[-1]):m.end(c[-1])], charSplitting(2,c))
#m = re.search(regex[3],sentence)
#if m:
#findings = m.groups()
#for c in zip(findings[::2], findings[1::2], range(0,len(findings),2)):
#sentence = sentence.replace(sentence[m.start(c[-1]):m.end(c[-1])], charsplitting(3,c))
return sentence
Removing stopping abbreviations¶
In order to increase the performance of our tokenizer, we need to get rid of annoying abbreviations that are followed by punctuation. To achieve that, I loaded some common german abbreviations into a .txt-file. These will be loaded by calling initializeAbbreviations. This is once called if the list doesn't exist yet.
def isUpperInBetween(word):
for char in word[1:]:
if char.isupper():
return True
return False
def initializeAbbreviations(custom_list, delete_specific):
abbr_temp = []
abbr_final = []
consonants = ["b", "c", "d", "f", "g", "h", "j", "k", "l", "m", "n", "p", "q", "r", "s", "ß", "t", "v", "w", "x", "z"]
with open("german_abbreviations.txt", "r") as file:
abbr_temp = file.readlines()
ending_to_keep = ["ss", "ng", "tz", "st", "bs", "ps", "ls", "gs", "rs", "ns", "ms", "ks", "ts", "rd", "rn", "rm", "rt", "rd", "rg", "rb", "rl", "rp"]
for i in abbr_temp:
i = i.split("\n")[0]
if "#" not in i:
if isUpperInBetween(i) or (len(i) > 2 and i[-2].lower() in consonants and i[-3].lower() in consonants and i not in abbr_final and i[-3:-1] not in ending_to_keep):
abbr_final.append(i)
abbr_final.append(i.capitalize())
# Delete specific abbreviations due to their role they could play (important for some tasks)
if len(delete_specific):
for d in delete_specific:
abbr_final.remove(d)
adds = ["z.B.", "z.b.","z. b.","etc.","e.t.c.","et.c.","u.a.","u.ä.","o.ä.","jährl.","St."]
adds.extend([a.capitalize() for a in adds])
abbr_final.extend(adds)
abbr_final.extend(custom_list)
return abbr_final
def removeAbbreviations(text, custom_list = [], delete_specific = []):
global abbr_german_final
if not 'abbr_german_final' in globals():
abbr_german_final = initializeAbbreviations(custom_list, delete_specific)
print("Abbreviations loaded...")
listing_regex = "^[A-Za-z0-9]{1}['.'|')']{1}"
regex = re.findall(listing_regex,text)
new_text = "".join([string+" " if string not in abbr_german_final else string.replace(".","")+" " for string in text.split(" ")])
if listing_regex:
new_text = "".join([string+" " for string in new_text.split(" ") if string not in regex])
return new_text.strip()
Dealing with special characters #smileys¶
There are some specific task which require smileys to be marked properly. To do that, I have implemented a function to deal with smileys and hashtags in different ways. This function can do the following:
- Being able to identify smileys correctly using regex
- Keeping emojis with a placeholder containing the polarity (matching table) or removing them completely
- By setting
keep_emoticonstoFalse, you erase them - setting it toTruemeans that we keep the polarity
- By setting
def handleEmojis(text, keep_emoticons = False):
global emoji_sentiment_matching
if not 'emoji_sentiment_matching' in globals():
with io.open('emojis.json', 'r', encoding = "UTF-8") as outfile:
emoji_sentiment_matching = json.load(outfile)
HASHTAG_PATTERN = re.compile(r'#\w*')
EMOJIS_PATTERN_PLAIN_TEXT = re.compile(r"(?:X|:|;|=)(?:-)?(?:\)|\(|O|D|P|S){1,}", re.IGNORECASE)
EMOJIS_PATTERN_SYMBOLS = re.compile(u'[\U00002600-\U000027BF]|[\U0001f300-\U0001f64F]|[\U0001f680-\U0001f6FF]')
if keep_emoticons:
# Replace emoji with sentiment
for emoji in emoji_sentiment_matching:
if emoji["emoji"] in text:
## Adding space if text follows right away / is right before the emoticon
idx = text.find(emoji["emoji"])
(space1,space2) = ("","")
if (idx-1) >= 0 and text[idx-1] != " ":
space1 = " "
if (idx+1) <= len(text) and text[idx+1] != " ":
space2 = " "
## replace emoticon with its sentiment
text = text.replace(emoji["emoji"], "{}emoji%%{}{}".format(space1, emoji["polarity"], space2))
## TO IMPLEMENT: Sentiment of other emoticons like :), :-), :-/
else:
for r in re.findall(EMOJIS_PATTERN_SYMBOLS,text):
text = text.replace(r, "")
for r in re.findall(EMOJIS_PATTERN_PLAIN_TEXT,text):
text = text.replace(r, "")
return text.strip()
Edit words that are separated by hyphens¶
There are some words which are not caught by our charSplitting function. These must be merged because some words are written differently by some people. This is a very crucial task that influences a lot of words. We must be careful how we use it.
The key for this to work is that we watch out for the lenghts of the words. When the first part of the hyphen-separated word is only one character long, we ignore the rule of splitting and merge the words together. This can be helpful when you look at the following example:
E-Mail=>E|Mail, we don't want these to be separated
def expandCompoundToken(text, split_chars="-"):
new_text = text
for t in text.split():
parts = []
add = False # signals if current part should be appended to previous part
for p in t.split(split_chars): # for each part p in compound token t
if not p: continue # skip empty part
if add and parts: # append current part p to previous part
parts[-1] += p
else: # add p as separate token
parts.append(p)
add = len(p) <= 1 # if p only consists of a single character -> append the next p to it
if len(parts)>0:
new_text = new_text.replace(t, " ".join(parts))
return new_text
Tokenization¶
It's all about separating a text into sentences and words. Tokenization is one of the crucial tasks which often tends to be a bottleneck for classification. We want to make sure that we know about the specific features in the text that is, the role of a word like NOUN or VERB. We can only do this if we are sure about where a sentence starts and ends. If you used common sense to tackle this problem, you would think of separating sentences by punctuation. That is basically the idea but actually considering real-world examples makes clear which problem we're talking about:
Please give Mr.|Thomas advice for his loan.|His E-Mail is peter.|thomas@xyz.|com.
These are two sentences. But a simple sentence splitter would not recognize these two. So I used the SpaCy library after cleaning up all we've talked about before. This library uses trained models to first split the sentences and then predict a word's role in it. Using a trained German model, we can also predict other word features. These include the following:
- Lemmas:
- Lemmas are the dictionary form of a word. This model brought by SpaCy enables us to decrease redundancy even more. Plural words are made singular as well as verbs are brought to a stem form.
https://dictionary.cambridge.org/de/worterbuch/englisch/lemma >> Lemma is a form of a word that appears as an entry in a dictionary and is used to represent all the other possible forms. For example, the lemma "build" represents "builds", "building", "built", etc.
- Lemmas are the dictionary form of a word. This model brought by SpaCy enables us to decrease redundancy even more. Plural words are made singular as well as verbs are brought to a stem form.
- POS Tags = Part-Of-Speech Tags
- These are the tags for each word which tell us which role this word has in a sentence. This can be quite interesting to take into account when different sentence types are used.
Fine Grained POS Tagsmore deeply show the meaning of a word in a sentence. In the following, a short illustration will show how that looks like:
- These are the tags for each word which tell us which role this word has in a sentence. This can be quite interesting to take into account when different sentence types are used.

Source: https://c1.sfdcstatic.com/content/dam/web/en_us/www/images/einstein/publications/example_kazuma.svg)
This graphic shows an idea how it looks like. Though, don't confuse yourself with the dependency parsing - this is not important for the tags themselves.
Prefix and Suffix
- These are straightforward features of words which contain either the first letter (Prefix) or the last 3 letters (Suffix). These can be interesting to analyze in cases like language identification or POS Tagging from scratch.
Shape
- These shapes are coming from how the word is actually written. It distinguishes between capital and lowercase characters and is returned in the following way: Word => Xxxx, word = xxxx, POSTagging => XXXXxxxxxx
Sentiment
- This method is good for differentiation between meanings of words regarding 'mood' of words.
Goodorbadwould then be categorized differently.
- This method is good for differentiation between meanings of words regarding 'mood' of words.
Sentences
- This is useful when you need to separate documents into sentences. This would then extend the text corpus to more redundancy but might increase accuracy slightly.
def getTokenString(text):
token = []
for t in nlp(text):
token.append(t.text)
return token
def getLemmas(text):
lemmas = []
for t in nlp(text):
lemmas.append(t.lemma_)
return lemmas
def getPOS(text):
pos_tags = []
for t in nlp(text):
pos_tags.append(t.pos_)
return pos_tags
def getFineGrainedPOS(text):
pos_tags = []
for t in nlp(text):
pos_tags.append(t.tag)
return pos_tags
def getShape(text):
shape = []
for t in nlp(text):
shape.append(t.shape_)
return shape
def getPrefix(text):
prefix = []
for t in nlp(text):
prefix.append(t.prefix_)
return prefix
def getSuffix(text):
suffix = []
for t in nlp(text):
suffix.append(t.suffix_)
return suffix
def getSentiment(text, n = 3):
sentiment = []
for t in nlp(text):
sentiment.append(t.sentiment)
return sentiment
def makeSentence(text):
sentences = []
for s in nlp(text).sents:
sentences.append(s)
return sentences
Basic Feature Extraction¶
Though, there will be a complete notebook about feature extraction of text, we will get some basic features of the passages. These include number of characters, number of vocals and consonants which tell us specificities of a certain text. These sometimes help us when using Machine Learning algorithms to classify.
def getWordFeatures(text, which_special_char = []):
VOCALS = []
CONSONANTS = ["b", "c", "d", "f", "g", "h", "j", "k", "l", "m", "n", "p", "q", "r", "s", "ß", "t", "v", "w", "x", "z"]
special_chars = ["#","(",")","<",">","§","@","€","$","&","%","{","}","^","[","]","=","*","+"]
NUMERICS = [str(i) for i in range(0,10)]
if len(which_special_char) > 0:
special_chars = which_special_char
vocals_count = 0
consonants_count = 0
char_count = len(text)
special_char_count = 0
uppercase_count = 0
numeric_count = 0
question_mark_count = 0
exclamation_mark_count = 0
for char in text:
if char.lower() in CONSONANTS:
consonants_count += 1
else:
vocals_count += 1
if char in special_chars:
special_char_count += 1
if char in NUMERICS:
numeric_count += 1
if char == '?':
question_mark_count += 1
if char == '!':
exclamation_mark_count += 1
if char.isupper():
uppercase_count += 1
return (vocals_count,
consonants_count,
char_count,
special_char_count,
uppercase_count,
numeric_count,
question_mark_count,
exclamation_mark_count)
getWordFeatures("Hallo boys, Wie gehts 10 ## !?")
N-grams¶
N-grams can be useful to find certain word combinations that are often used together. In consequence, we can use this method to extract valuable information like keyword matching or automatically develop a dictionary for word combinations which we could use to chain them together and increase classification results.
The standard value for n is 2 so that we find word pairs. But we can also pass other values for n to detect other patterns. As you can imagine, this could also work with word tags from which combinations we are able to gain information of.
## Input a list of tokens
def makeNgrams(token, n = 2):
result = []
for i in range(len(token)-(n-1)):
ngrams = (str(token[i]),)
for j in range(1,n):
ngrams = ngrams + (str(token[i+j]),)
result.append(ngrams)
return result
Returning the strings in one list¶
Language Detection¶
A really important aspect, we have to consider for a few use cases, is language itself. For some corpora, we might want to exclude certain languages, for he most cases though, we will prefer German as the main language (since most modules are specifically built for German language).
The library langdetect which is translated from Java into Python, is based on a Google's model for language detection and claims the following:
- Generate language profiles from Wikipedia abstract xml
- Detect language of a text using naive Bayesian filter
- 99% over precision for 53 languages
I built it by passing the languages to keep as parameter langs and building an exception-bridge which causes a text which is not properly detected to stay in the corpus. Otherwise, the text itself will be returned when being the required language or None will be returned for not being a required language.
Beware!¶
If you want to be 100% sure about preprocessing the whole corpus, this function will only lead 99% to your desired outcome!
from langdetect import detect
def languageDetector(text, langs=["de"]):
try:
if detect(text) in langs:
return text
else:
return ""
except:
return text
Removing Punctuation¶
After having removed specialities about the language, removing punctuation will lead to a cleaner dataset to handle. I'm leaving some space for manual improvements by using different levels of punctuation removement as well as the ability to pass yur own punctuation marks for removal punctuation to remove (manual_list).
Since we are dealing with tokens in this stage of preprocessing, the input will be a list of tokens.
def removePunctuation(token, level = 3, manual_list = []):
MARKS = [[],[],[]]
MARKS[0] = ['*', ',', ';', '<', '=', '>', '[', '\\', ']', '^', '_', '`', '{', '|', '}', '~', "'", "+", '“', '„', '.', ':']
# These marks can be important to catch specific sentiments or the connection between ideas
MARKS[1] = ['!', '(', ')', '-', '?', '/','"', '&','–']
# These might be important for catching email-adresses or specific relevant values
MARKS[2] = ['@', '$', '%', '€']
removals = []
new_token = token
if len(manual_list) > 0:
removals = manual_list
else:
for i in MARKS[:level]:
removals.extend(i)
for char in token:
if char in removals:
new_token = token.replace(char, "")
return new_token
Lowercase¶
Since we want to find out semantic relations between words, we have to equalize words that are written in different ways. These differences are, if you explicitely look at some sentences, words that are right in the beginning of a sentence or wihin the sentencem which have same meanings but are written with or without capital letters. Python makes it easy for us: We just have to use the lowerfunction that is already available in the Python Standard Library.
def toLower(text):
return text.lower()
Stemming¶
Credits: http://snowball.tartarus.org/
This is all about equalizing even more words. Especially in German, there are many verbforms having the same stem and having no differences in meaning. The Snowball stemmer algorithm helps us to bring all words in a shorter form so that we have have a "smaller dictionary" to deal wih later on. This is extremely useful when calculating Bag Of Words (BoW), Term frequency Inverse document frequency (TfIdf) or other vectorizing methods.
The Snowball Stemmer cuts of common word endings and returns the stem of the word.
I implemented this stemming algorithm for the languages, we're dealing with most of the times.
from nltk.stem.snowball import SnowballStemmer
def stemText(token, lang="de"):
langs = {
"de": "german",
"en": "english",
"es": "spanish",
"it": "italian"
}
stemmer = SnowballStemmer(langs[lang])
return stemmer.stem(token)
Removing stop words¶
Stop words are very common words which are used in any text. These mostly occur when connecting ideas or filling sentences for the general flow. In English, words like and, in or for are typical stopwords we can't assign a real meaning to.
I have found some lists for stopwords in either language. Like we did for punctuation, I want the user to manually be able to specify the level of how many stopwords get removed and also leave the possibility of passing an own stopword list.
Again, this will be done after preprocessing and we will pass each token at once.
from nltk.corpus import stopwords
def removeStopwords(token, lang="de", level=2, manual_list=[]):
STOPWORDS = {
"de": ["","stopwords_german.txt","stopwords_german_extended.txt"] # level 1 = normal, level 2 = extended
}
removals = manual_list
try:
with io.open(STOPWORDS[lang][level], "r", encoding = "UTF-8") as txt_file:
removals.extend(txt_file.readlines())
removals = [clean.replace("\n","").replace("\ufeff","") for clean in removals]
except:
pass
if token not in removals:
return token
else:
return None
Preprocessing Orchestrator¶
We will need a worker which gets the input and turns it into the desired preprocessed form. This is a task that is not trivial at all. We will have differently sturctured input that we want to return in different ways. The global scenarios for that are the following:
Handing over the documents in the same form:
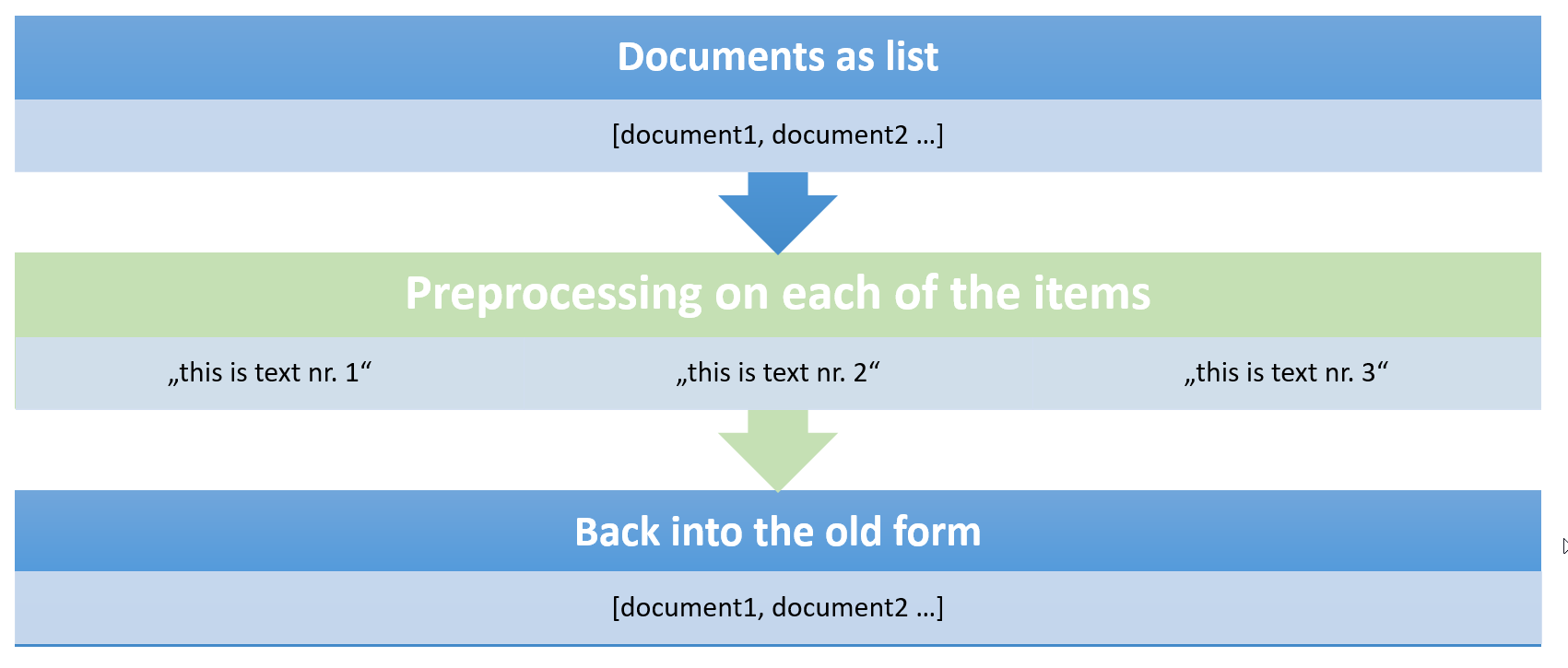
This is the most common scenario. We get documents as input and the user wants them to be returned as preprocessed documents.
Filtering:
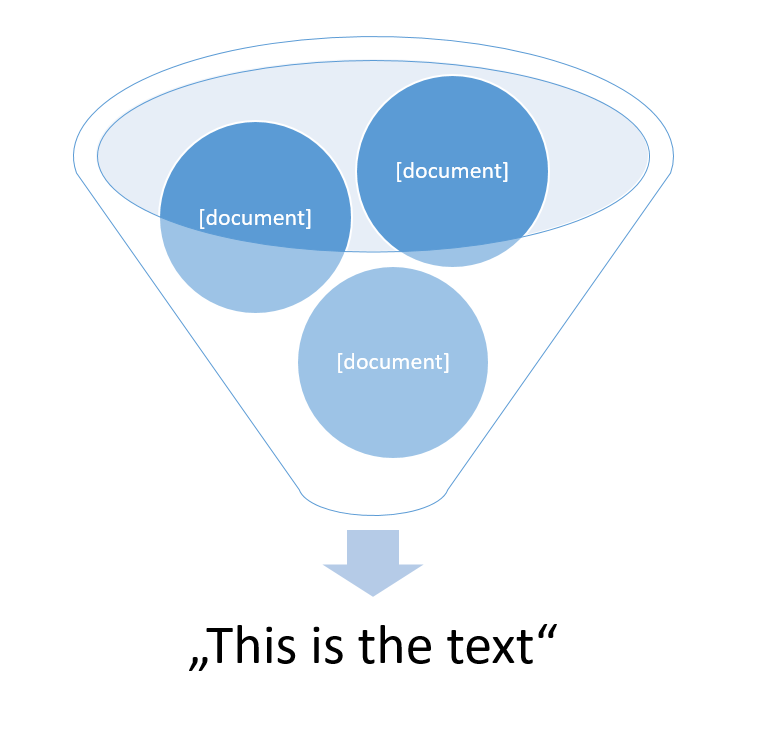
Here we have documents as input (lists with strings) of which the user wants to get each string returned. In this case, we will need the specific labels, so we can return these strings attached to them.
Define the function¶
To be able to fulfill these different needs, we will define a function in the following way:
def preprocess(X, args):
LEVEL_1 = OrderedDict({
"UnicodeCleaner": {
"method": unicodeCleaner,
"activated": True,
"arguments": {"seperator": args["unicode_seperator"]}
},
"RemoveUmlauts": {
"method": removeUmlauts,
"activated": False,
"arguments": {}
},
"RemoveAbbreviations": {
"method": removeAbbreviations,
"activated": False,
"arguments": {"custom_list" : args["custom_abbreviations"],
"delete_specific" : args["delete_abbreviations"]}
},
"HandleEmojis": {
"method": handleEmojis,
"activated": False,
"arguments": {"keep_emojis" : args["keep_emojis"]}
},
"RemoveGermanChainWords": {
"method": removeGermanChainWords,
"activated": False,
"arguments": {}
},
"ExpandCompoundToken": {
"method": expandCompoundToken,
"activated": False,
"arguments": {}
},
"LanguageDetector": {
"method": languageDetector,
"activated": False,
"arguments": {"langs":args["langs"]}
},
"MakeSentence": {
"method": makeSentence,
"activated": False,
"arguments": {}
}
})
LEVEL_2 = OrderedDict({
"Tokenization": {
"method": getTokenString,
"activated": False,
"arguments": {},
"end": False
},
"WordFeatures":{
"method": getWordFeatures,
"activated": False,
"arguments": {"which_special_char": args["which_special_char"]},
"end": True
},
"Lemmatization": {
"method": getLemmas,
"activated": False,
"arguments": {},
"end": False
},
"POSTagging": {
"method": getPOS,
"activated": False,
"arguments": {},
"end": True
},
"FineGrainedPOSTagging": {
"method": getFineGrainedPOS,
"activated": False,
"arguments": {},
"end": True
},
"Shape": {
"method": getShape,
"activated": False,
"arguments": {},
"end": True
},
"Prefix": {
"method": getPrefix,
"activated": False,
"arguments": {},
"end": True
},
"Suffix": {
"method": getSuffix,
"activated": False,
"arguments": {},
"end": True
},
"Sentiment": {
"method": getSentiment,
"activated": False,
"arguments": {},
"end": True
}
})
LEVEL_3 = OrderedDict({
"PunctuationFilter": {
"method": removePunctuation,
"activated": False,
"arguments": {"level":args["punctuation_level"],
"manual_list":args["punctuation_list"]}
},
##
## CURRENTLY ONLY WORKS WITH ONE LANGUAGE
"RemoveStopWords": {
"method": removeStopwords,
"activated": False,
"arguments": {"lang":args["langs"][0],
"level": args["stopword_level"],
"manual_list": args["custom_stopwords"]}
},
##
## CURRENTLY ONLY WORKS WITH ONE LANGUAGE
"StemText": {
"method": stemText,
"activated": False,
"arguments": {"lang":args["langs"][0]}
},
"ToLower": {
"method": toLower,
"activated": False,
"arguments": {}
}
})
LEVEL_4 = OrderedDict({
"MakeNgrams": {
"method": makeNgrams,
"activated": False,
"arguments": {"n" : args["n_gram_size"]}
}
})
for method in args["include"]:
if method in LEVEL_1:
LEVEL_1[method]["activated"] = True
if method in LEVEL_2:
LEVEL_2[method]["activated"] = True
if method in LEVEL_3:
LEVEL_3[method]["activated"] = True
if method in LEVEL_4:
LEVEL_4[method]["activated"] = True
# LEVEL 1: PRE-EDITING
#
level_1_doc = X
for method, args in enumerate(LEVEL_1):
if LEVEL_1[args]["activated"]:
level_1_doc = LEVEL_1[args]["method"](level_1_doc, **LEVEL_1[args]["arguments"])
# LEVEL 2: TOKENIZATION
#
level_2_doc = level_1_doc
for method, args in enumerate(LEVEL_2):
if LEVEL_2[args]["activated"]:
level_2_doc = LEVEL_2[args]["method"](level_2_doc, **LEVEL_2[args]["arguments"])
if LEVEL_2[args]["end"]:
return level_2_doc
break
# LEVEL 3: PROCESSING TOKENS
#
level_3_doc = level_2_doc
result_doc = []
for method, args in enumerate(LEVEL_3):
if LEVEL_3[args]["activated"]:
result_doc = []
for s in iterateStrings(level_3_doc,depth_calculator(level_3_doc)):
result_doc.append(LEVEL_3[args]["method"](s, **LEVEL_3[args]["arguments"]))
level_3_doc = result_doc
# LEVEL 4: OTHER TASKS
#
level_4_doc = level_3_doc
result_doc = []
for method, args in enumerate(LEVEL_4):
if LEVEL_4[args]["activated"]:
result_doc = []
for s in iterateStrings(level_4_doc,depth_calculator(level_4_doc)):
result_doc.append(LEVEL_4[args]["method"](s, **LEVEL_4[args]["arguments"]))
if len(result_doc) > 0:
level_4_doc = result_doc
return level_4_doc
from collections import OrderedDict
import sys
import time
def preprocessingOrchestrator(X, y = [], include = [], langs = ["de"],
labels_separated = True,
unicode_seperator = True,
keep_emojis= False,
custom_abbreviations= [],
delete_abbreviations= [],
custom_stopwords= [],
stopword_level= 1,
n_gram_size= 2,
punctuation_level= 3,
punctuation_list = [],
which_special_char = [], **others):
# You are able to pass the following arguments
details = {
"include" : include,
"langs" : langs,
"labels_separated" : labels_separated,
"unicode_seperator" : unicode_seperator,
"keep_emojis" : keep_emojis,
"custom_abbreviations" : custom_abbreviations,
"delete_abbreviations" : delete_abbreviations,
"custom_stopwords" : custom_stopwords,
"stopword_level" : stopword_level,
"n_gram_size" : n_gram_size,
"punctuation_level" : punctuation_level,
"punctuation_list" : punctuation_list,
"which_special_char" : which_special_char
}
start = time.time()
counter = 0
length = countMultidimensionalList(X)
X_new = []
y_new = []
if len(y) > 0:
#print("Filtering...")
### Filtering method
if len(include) == 0:
return X_new, y
if type(X) is str:
return preprocess(X, details)
elif depth(X) == depth(y):
for text, label in zip(iterateStrings(X, depth(X)),iterateStrings(y, depth(X))):
X_new.append(preprocess(text, details))
y_new.append(label)
else:
for text, pos in iterateStringsWithPosition(X, depth(X), depth(X)):
X_new.append(preprocess(text, details))
y_new.append(y[pos[0]])
counter+=1
# SHOW PERCENTAGE
print("Preprocessing: {} %".format(round(counter/length*10000)/100), end="\r")
end = time.time()
print("Time Elapsed: {} min.".format(round((end-start)/60*100)/100))
return X_new, y_new
else:
if len(include) == 0:
return X, []
#print("Same form...")
if type(X) is str:
return preprocess(X, details)
X_new = copy.deepcopy(X)
overall_depth = depth(X)
for text,pos in iterateStringsWithPosition(X, overall_depth, overall_depth):
final = preprocess(text, details)
nr = 0
current = copy.deepcopy(X_new)
for i in pos:
if type(current) == list:
current = copy.deepcopy(current[i])
nr+=1
else:
break
if nr == 1:
X_new[pos[0]] = final
elif nr == 2:
X_new[pos[0]][pos[1]] = final
elif nr == 3:
X_new[pos[0]][pos[1]][pos[2]] = final
elif nr == 4:
X_new[pos[0]][pos[1]][pos[2]][pos[3]] = final
elif nr == 5:
X_new[pos[0]][pos[1]][pos[2]][pos[3]][pos[4]] = final
counter+=1
# SHOW PERCENTAGE
print("Preprocessing: {} %".format(round(counter/length*10000)/100), end="\r")
end = time.time()
print("Time Elapsed: {} min.".format(round((end-start)/60*100)/100))
return X_new, []